社团项目需求,需要测试一下核显+opencl+tvm与独显+tensorrt的速度。因为之前对神经网络这块的练习甚少,就记录了一下。
前言
社团项目需求,需要测试一下集显+opencl+tvm与独显+tensorrt的速度
因为之前对神经网络这块的练习甚少,就记录了一下。
7.5更新:由于tvm对nuc上的核显支持度不好,以及作者水平有限()本文仅作为一个安装教程参考,其测试代码和实验结果可靠性无法确定。
参考网址
安装
测试
步骤
opencl
sudo apt install ocl-icd-libopencl1
sudo apt install opencl-headers
sudo apt install clinfo
sudo apt install ocl-icd-opencl-dev
#sudo apt install beignet
sudo add-apt-repository ppa:intel-opencl/intel-opencl
sudo apt update
sudo apt install intel-opencl-icd
tvm
sudo apt-get install llvm
git clone --recursive https://github.com/dmlc/tvm.git
sudo apt-get update
sudo apt-get install -y python python-dev python-setuptools gcc libtinfo-dev zlib1g-dev
cd tvm $$ mkdir build
cp cmake/config.cmake build
修改build/config.cmake
由于用的是集显电脑,没法set(USE_CUDA OFF) 到 set(USE_CUDA ON)
但可以
set(USE_LLVM ON)
set(USE_OPENCL ON)
cd build
cmake ..
make -j4
编辑.bashrc配置Python环境
export TVM_HOME=/home/xxxx/code/tvm(tvm的github下载目录)
export PYTHONPATH=$TVM_HOME/python:$TVM_HOME/topi/python:$TVM_HOME/nnvm/python
source一下
如果您只是想配环境,看到这里就可以啦~
测试
修改tvm目录下的tutorials/frontend/from_pytorch.py,添加运行速度记录
import tvm
from tvm import relay
import datetime
import numpy as np
import tvm.contrib.graph_runtime as runtime
from tvm.contrib.download import download_testdata
# PyTorch imports
import torch
import torchvision
######################################################################
# Load a pretrained PyTorch model
# -------------------------------
model_name = 'resnet50'
model = getattr(torchvision.models, model_name)(pretrained=True)
model = model.eval()
# We grab the TorchScripted model via tracing
input_shape = [1, 3, 224, 224]
input_data = torch.randn(input_shape)
scripted_model = torch.jit.trace(model, input_data).eval()
######################################################################
# Load a test image
# -----------------
# Classic cat example!
from PIL import Image
img_url = 'https://github.com/dmlc/mxnet.js/blob/master/data/cat.png?raw=true'
img_path = download_testdata(img_url, 'cat.png', module='data')
img = Image.open(img_path).resize((224, 224))
# Preprocess the image and convert to tensor
from torchvision import transforms
my_preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = my_preprocess(img)
img = np.expand_dims(img, 0)
######################################################################
# Import the graph to Relay
# -------------------------
# Convert PyTorch graph to Relay graph. The input name can be arbitrary.
input_name = 'input0'
shape_list = [(input_name, img.shape)]
mod, params = relay.frontend.from_pytorch(scripted_model,
shape_list)
######################################################################
# Relay Build
# -----------
# Compile the graph to llvm target with given input specification.
target = 'opencl'
ctx = tvm.opencl()
with tvm.transform.PassContext(opt_level=3):
graph, lib, params = relay.build(mod,
target=target,
params=params)
######################################################################
# Execute the portable graph on TVM
# ---------------------------------
# Now we can try deploying the compiled model on target.
from tvm.contrib import graph_runtime
dtype = 'float32'
m = graph_runtime.create(graph, lib, ctx)
# Set inputs
m.set_input(input_name, tvm.nd.array(img.astype(dtype)))
m.set_input(**params)
start=datetime.datetime.now()
# Execute
m.run()
end=datetime.datetime.now()
# Get outputs
tvm_output = m.get_output(0)
#####################################################################
# Look up synset name
# -------------------
# Look up prediction top 1 index in 1000 class synset.
synset_url = ''.join(['https://raw.githubusercontent.com/Cadene/',
'pretrained-models.pytorch/master/data/',
'imagenet_synsets.txt'])
synset_name = 'imagenet_synsets.txt'
synset_path = download_testdata(synset_url, synset_name, module='data')
with open(synset_path) as f:
synsets = f.readlines()
synsets = [x.strip() for x in synsets]
splits = [line.split(' ') for line in synsets]
key_to_classname = {spl[0]:' '.join(spl[1:]) for spl in splits}
class_url = ''.join(['https://raw.githubusercontent.com/Cadene/',
'pretrained-models.pytorch/master/data/',
'imagenet_classes.txt'])
class_name = 'imagenet_classes.txt'
class_path = download_testdata(class_url, class_name, module='data')
with open(class_path) as f:
class_id_to_key = f.readlines()
class_id_to_key = [x.strip() for x in class_id_to_key]
# Get top-1 result for TVM
top1_tvm = np.argmax(tvm_output.asnumpy()[0])
tvm_class_key = class_id_to_key[top1_tvm]
# Convert input to PyTorch variable and get PyTorch result for comparison
with torch.no_grad():
torch_img = torch.from_numpy(img)
start2=datetime.datetime.now()
output = model(torch_img)
end2=datetime.datetime.now()
# Get top-1 result for PyTorch
top1_torch = np.argmax(output.numpy())
torch_class_key = class_id_to_key[top1_torch]
print('Relay top-1 id: {}, class name: {}'.format(top1_tvm, key_to_classname[tvm_class_key]))
print('>>TVM cost %.2f ms' %
(((end - start).seconds*1000.0 + (end - start).microseconds/1000.0)))
print('Torch top-1 id: {}, class name: {}'.format(top1_torch, key_to_classname[torch_class_key]))
print('>>Torch cost %.2f ms' %
(((end2 - start2).seconds*1000.0 + (end2 - start2).microseconds/1000.0)))
# evaluate2
module = runtime.create(graph, lib, ctx)
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=1,repeat=600)
prof_res = np.array(ftimer().results) * 1000 # convert tomillisecond
print("Mean inference time (std dev): %.2f ms (%.2f ms)" %
(np.mean(prof_res), np.std(prof_res)))
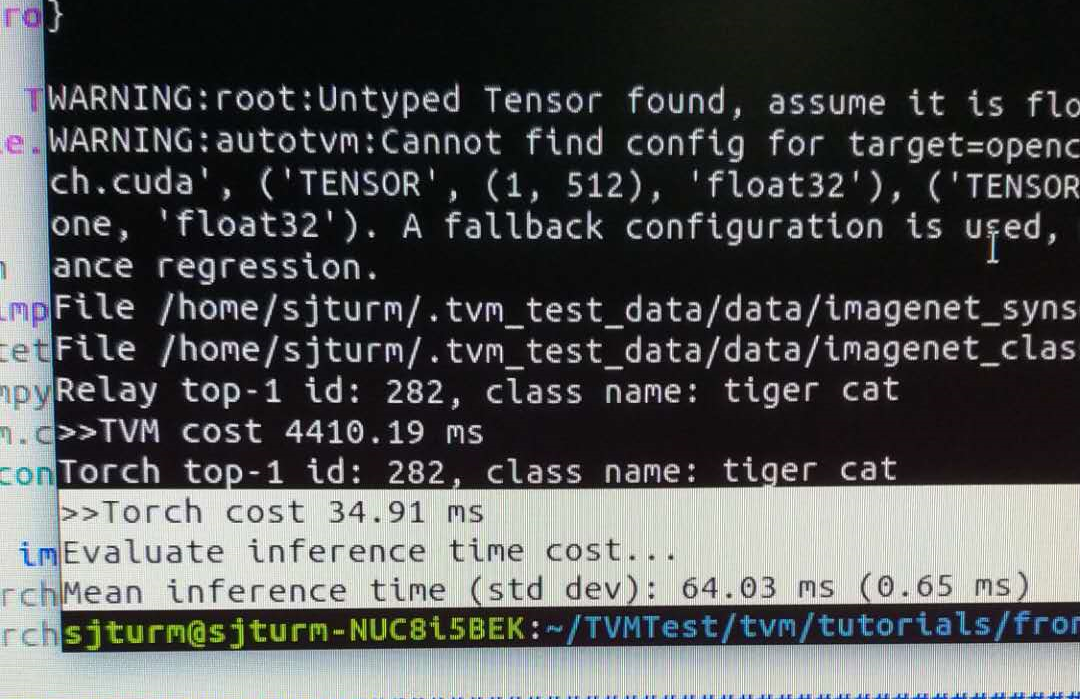
这个速度貌似是不对的,由于还没有加auto tune
autotune的代码如下
import os
import numpy as np
import tvm
from tvm import te
from tvm import autotvm
from tvm import relay
import tvm.relay.testing
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.contrib.util import tempdir
import tvm.contrib.graph_runtime as runtime
def get_network(name, batch_size):
"""Get the symbol definition and random weight of a network"""
input_shape = (batch_size, 3, 224, 224)
output_shape = (batch_size, 1000)
if "resnet" in name:
n_layer = int(name.split('-')[1])
mod, params = relay.testing.resnet.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)
elif "vgg" in name:
n_layer = int(name.split('-')[1])
mod, params = relay.testing.vgg.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)
elif name == 'mobilenet':
mod, params = relay.testing.mobilenet.get_workload(batch_size=batch_size, dtype=dtype)
elif name == 'squeezenet_v1.1':
mod, params = relay.testing.squeezenet.get_workload(batch_size=batch_size, version='1.1', dtype=dtype)
elif name == 'inception_v3':
input_shape = (1, 3, 299, 299)
mod, params = relay.testing.inception_v3.get_workload(batch_size=batch_size, dtype=dtype)
elif name == 'mxnet':
# an example for mxnet model
from mxnet.gluon.model_zoo.vision import get_model
block = get_model('resnet18_v1', pretrained=True)
mod, params = relay.frontend.from_mxnet(block, shape={'data': input_shape}, dtype=dtype)
net = mod["main"]
net = relay.Function(net.params, relay.nn.softmax(net.body), None, net.type_params, net.attrs)
mod = tvm.IRModule.from_expr(net)
else:
raise ValueError("Unsupported network: " + name)
return mod, params, input_shape, output_shape
#### DEVICE CONFIG ####
target = 'opencl'
#### TUNING OPTION ####
network = 'resnet-18'
log_file = "%s.log" % network
dtype = 'float32'
tuning_option = {
'log_filename': log_file,
'tuner': 'xgb',
'n_trial': 2000,
'early_stopping': 600,
'measure_option': autotvm.measure_option(
builder=autotvm.LocalBuilder(timeout=10),
runner=autotvm.LocalRunner(number=20, repeat=3, timeout=4, min_repeat_ms=150),
#runner=autotvm.RPCRunner(
#'1080ti', # change the device key to your key
#'0.0.0.0', 9190,
#number=20, repeat=3, timeout=4, min_repeat_ms=150)
),
}
def tune_tasks(tasks,
measure_option,
tuner='xgb',
n_trial=1000,
early_stopping=None,
log_filename='tuning.log',
use_transfer_learning=True):
# create tmp log file
tmp_log_file = log_filename + ".tmp"
if os.path.exists(tmp_log_file):
os.remove(tmp_log_file)
for i, tsk in enumerate(reversed(tasks)):
prefix = "[Task %2d/%2d] " %(i+1, len(tasks))
# create tuner
if tuner == 'xgb' or tuner == 'xgb-rank':
tuner_obj = XGBTuner(tsk, loss_type='rank')
elif tuner == 'ga':
tuner_obj = GATuner(tsk, pop_size=100)
elif tuner == 'random':
tuner_obj = RandomTuner(tsk)
elif tuner == 'gridsearch':
tuner_obj = GridSearchTuner(tsk)
else:
raise ValueError("Invalid tuner: " + tuner)
if use_transfer_learning:
if os.path.isfile(tmp_log_file):
tuner_obj.load_history(autotvm.record.load_from_file(tmp_log_file))
# do tuning
tsk_trial = min(n_trial, len(tsk.config_space))
tuner_obj.tune(n_trial=tsk_trial,
early_stopping=early_stopping,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(tsk_trial, prefix=prefix),
autotvm.callback.log_to_file(tmp_log_file)
])
# pick best records to a cache file
autotvm.record.pick_best(tmp_log_file, log_filename)
os.remove(tmp_log_file)
def tune_and_evaluate(tuning_opt):
# extract workloads from relay program
print("Extract tasks...")
mod, params, input_shape, out_shape = get_network(network, batch_size=1)
tasks = autotvm.task.extract_from_program(mod["main"], target=target,
params=params,
ops=(relay.op.get("nn.conv2d"),))
# run tuning tasks
print("Tuning...")
tune_tasks(tasks, **tuning_opt)
# compile kernels with history best records
with autotvm.apply_history_best(log_file):
print("Compile...")
with tvm.transform.PassContext(opt_level=3):
graph, lib, params = relay.build_module.build(
mod, target=target, params=params)
# export library
tmp = tempdir()
filename = "net.tar"
lib.export_library(tmp.relpath(filename))
# load parameters
ctx = tvm.context(str(target), 0)
module = runtime.create(graph, lib, ctx)
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype(dtype))
module.set_input('data', data_tvm)
module.set_input(**params)
# evaluate
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=1, repeat=600)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
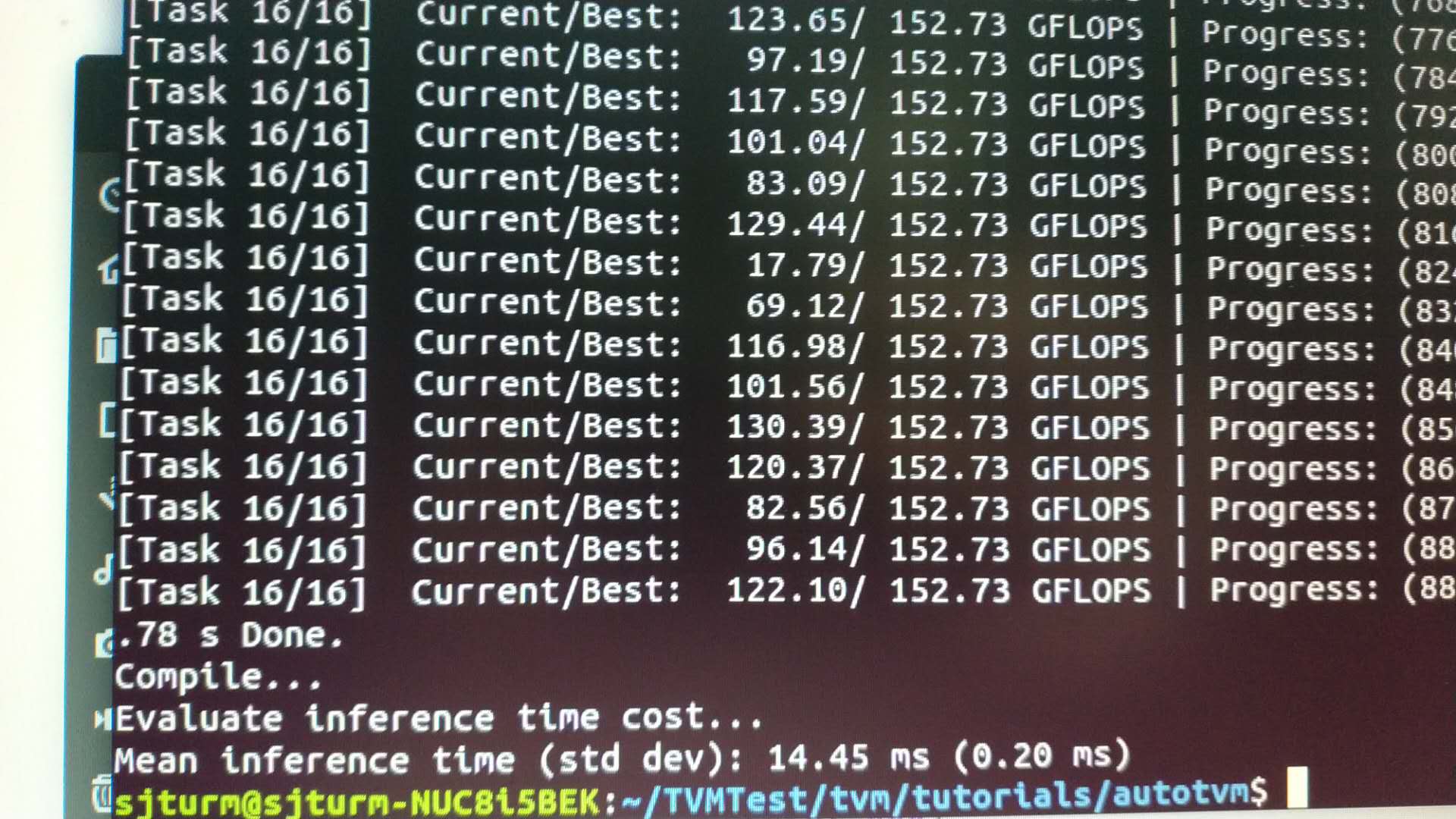
print("Mean inference time (std dev): %.2f ms (%.2f ms)" %
(np.mean(prof_res), np.std(prof_res)))
# We do not run the tuning in our webpage server since it takes too long.
# Uncomment the following line to run it by yourself.
tune_and_evaluate(tuning_option)
直接运行,跑了一个晚上,终于出结果了,如下(14ms)因为怕resnet50时间太长,改成了resnet18,fp32,自然,失去了横向对比的意义,但可以纵向对比。经过autotune,运算速度确实可以大幅提高
TRT端
在trt安装目录下的bin目录中打开终端,执行
./trtexec --output=prob --deploy=/home/k/RM/TensorRT-6.0.1.5/data/resnet50/ResNet50_N2.prototxt --batch=1
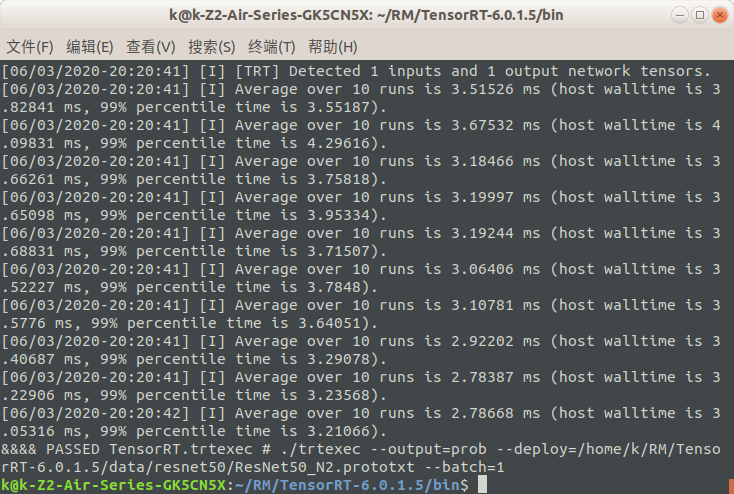
差距有点大,分析原因(1)target设置可能有问题(2)这种方式不适合本设备